Using core.async for Producer-Consumer Workflows
I’ve found core.async to be versatile for many workflows. One that I’ve used on several occasions is a producer-consumer model to distribute work among multiple consumers.
Say we want to process a lot of data coming in from a single source (e.g. stdin) and then output the results to a single destination (e.g. stdout). We can think of this as a producer-consumer problem.

A naive solution may look like this:
(defn process
"Do 'work'"
[line]
(Thread/sleep 10))
(def stdin-reader
(java.io.BufferedReader. *in*))
;; Read each line from stdin
(doseq [line (line-seq stdin-reader)]
(process line)
(println line))But if process is expensive, we would find this program unacceptably slow. On my machine, this baseline program takes 115.5 seconds using 9% of the CPU to process 10,000 lines.
How can we speed this up?
It’s apparent that our program isn’t taking advantage of our CPU—we’re only using 9% of it. We should deploy threads! Perhaps we can use java.util.concurrent.Executors to deploy a pool of workers, where each worker outputs their work into a shared Java concurrent queue. Another thread can then consume from this queue to print to stdout.
A simple alternative
A simple alternative is to use core.async. Using core.async’s thread macro, we can create consumers that take data from an input channel, process the data, and put the result to an output channel.
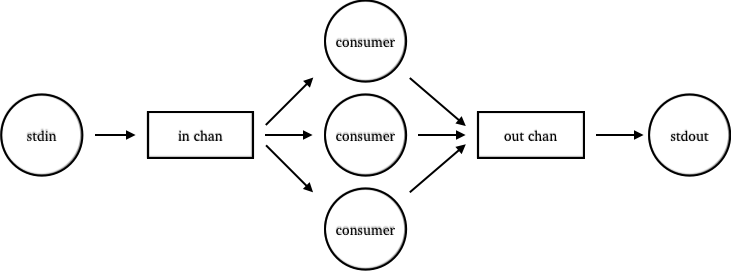
To do this, we’ll first create our two channels:
(ns my-test-ns
(:require [clojure.core.async :as async]))
(defn process [line]
(Thread/sleep 10)
line)
(def stdin-reader
(java.io.BufferedReader. *in*))
(def in-chan (async/chan))
(def out-chan (async/chan))Then, using thread, we’ll create consumers that live in its own threads so that they can do blocking takes and puts. We could use a go block here, which would employ its own thread pool, but I’ve found that go threads result in less throughput than devoted threads for CPU-heavy work. Our consumers look like this:
(defn start-async-consumers
"Start num-consumers threads that will consume work
from the in-chan and put the results into the out-chan."
[num-consumers]
(dotimes [_ num-consumers]
(async/thread
(while true
(let [line (async/<!! in-chan)
data (process line)]
(async/>!! out-chan data))))))Note that async/thread instantly returns a channel that will receive the result of the body. We ignore the return value, however, since our consumers are long-living.
Then we’ll print out the processed items by taking from the output channel:
(defn start-async-aggregator
"Take items from the out-chan and print it."
[]
(async/thread
(while true
(let [data (async/<!! out-chan)]
(println data)))))Finally we can start our program:
(do
(start-async-consumers 8)
(start-async-aggregator)
(doseq [line (line-seq stdin-reader)]
(async/>!! in-chan line)))This core.async version ran in 20.086 seconds using 54% of the CPU to process 10,000 lines. Compared to the 115.5 seconds of the baseline program, this version is almost six times faster.
Naturally, there are cases where we should prefer Java’s Executors library to core.async. In fact, thread does use Executors underneath the hood. But why not take advantage of core.sync? You’ll get the benefits of core.async channels and operations on top of thread’s simplicity for producer-consumer workflows.
For further study
Rich Hickey: Clojure core.async Channels
Timothy Baldridge: Core.Async (video)